Models Post-Training - 25
Welcome,
1. Post-training
1.1 Model Editing
- ACL 2024 - An Easy-to-use Knowledge Editing Framework for LLMs
- Easy Edit
- ROME (ICLR 2023): Locating and Editing Factual Knowledge in GPT
- MEMIT (2023): Mass Editing Memory in Transformers
1.2 Model Merging
- MergeKit - Tools for merging pretrained LLMs
- 2025 Mergenetic - A Simple Evolutionary Model Merging Library
- 2021 Task Arithmetic - Linear combination of model weights
- LoRA Merging - Fusion of multiple LoRA adapters
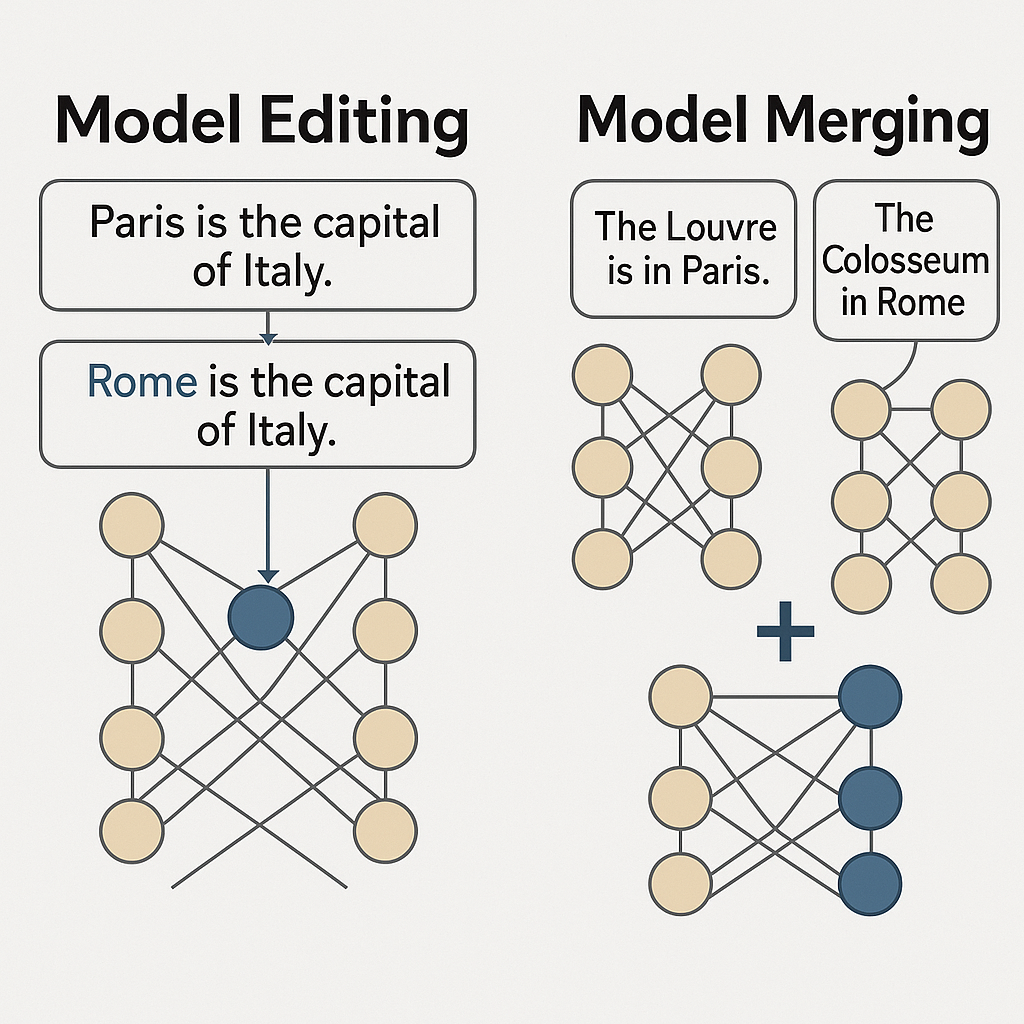
1.3 Machine Un-Learning
1.4 Hard to modify – update knowledge to LMs
2. Multi-LLM Agent
3. Why Can Neural Networks Be Compressed
1. Redundancy
Most neural networks contain abundant redundant parameters Many weights contribute minimally to final predictions Network capacity typically exceeds actual requirements
2. Over-parameterization
Modern NNs often have millions to billions of parameters Actual tasks may only require a small subset Large capacity needed for training, but can be streamlined for inference
References
Enjoy Reading This Article?
Here are some more articles you might like to read next: